ChatGPTのサイト参照と仕組み
WebPitaが観測で利用している仕組みです。
ChatGPTはサイトをどう参照するか、AI流入の仕組みとボットの識別方法を解説します。 ChatGPT(およびその基盤となるOpenAIのモデル)がウェブ上の情報を収集する仕組みは、主に「GPTBot」と呼ばれるウェブクローラーを介して行われます。
AIは主に「情報収集」と「回答生成」という2つのプロセスでWebにアクセスをしてきます。
Webサイトは、AIにとって重要な情報源です。AIはWeb上のページを参照しながら回答を生成し、その結果がユーザーに提示されます。
また、回答内のリンクや情報を通じて、ユーザーがWebサイトへ訪問する流れも発生します。
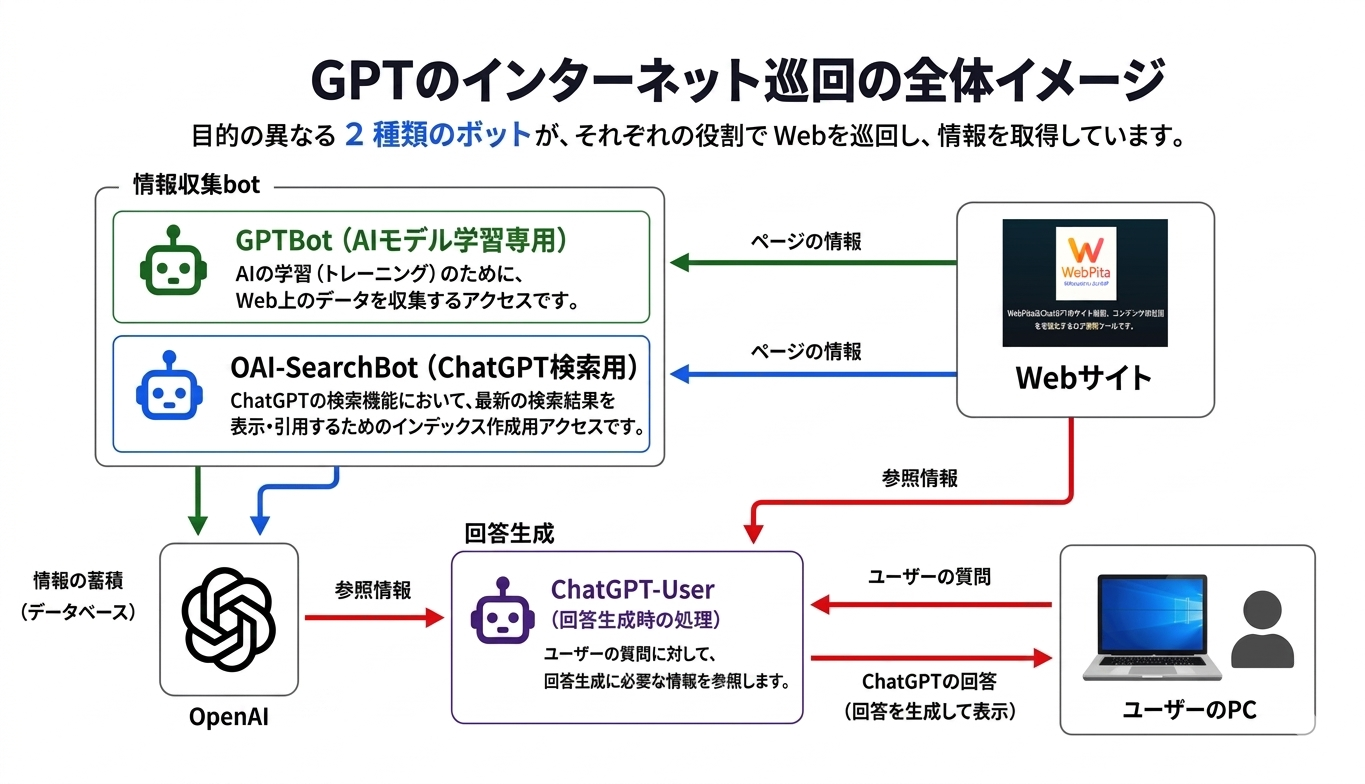
GPTのクローラー(Bot)には、目的別にいくつかの種類が存在します。特に2026年現在、AI検索や自律型エージェントの普及により、その役割はより細分化されています。
OpenAIではこれらのBotの接続IPを「公式IP帯域」に記載しています。正しく認識する為には加えて「User-Agent(UA)」を確認する必要があります。
最新情報を公式URLより確認をしてください。
OpenAI公式:ボットに関するドキュメント
巡回Bot(AI学習データ収集をするBot)
OpenAIのAIモデル学習(トレーニング)のために、Web上のデータを収集するアクセスです。
検索エンジン用の情報収集bot
ChatGPTの検索機能において、最新のニュースや情報を引用・表示するためのアクセスです。AIO(AI最適化)において最も重要なBotです。
GPTが回答生成時に訪問
ユーザーの質問に対し、ChatGPTが回答の材料としてサイトを閲覧したアクセスです。
※回答の候補として検討されたことを示しており、最終的な採用(引用)の有無は含みません。
外部機能・API連携
カスタムGPT(GPTs)などを通じて、ユーザーが特定の機能実行やデータ連携を行った際の動作です。
OAI-AdsBotは広告判定bot
OAI-AdsBotは、広告コンテンツの安全性と関連性を検証する役割を担います。
主な動作は、広告ランディングページへの巡回によるポリシー遵守の確認、および表示ロジックの最適化です。特定の広告用URLに対してのみアクセスを行い、取得したデータは生成AIの基礎モデル学習には転用されない仕組みとなっています。
ユーザ
ChatGPTの回答や検索結果のリンクをきっかけとした、実際のユーザーがWebサイトに訪問してきます。
この識別子として、リクエストURLに"utm_source=chatgpt.com"が付加されます。これにより、ChatGPT経由で実際にユーザーが訪問したことを検知できます。